Speculative Decoding with vLLM
When deploying large language models in production environments, latency optimization is crucial. This is particularly important for real-time applications like chatbots and conversational interfaces. While complex tasks often require larger LLMs (70 billion+ parameters), users still expect response times similar to smaller models. This challenge has led the machine learning community to continuously explore new ways to improve LLM latency.
One of the most promising techniques is speculative decoding, which is a technique that improves the performance of a language model by predicting multiple tokens at a time with a smaller model and use a larger model to validate the predictions.
Problem
When serving large language models in production, you need to lower the latency. In fact, latency optimization is the biggest challenge that developers will face in production LLM systems. This challenge becomes particularly acute in real-time scenarios, where users expect near-instantaneous interactions with chatbots, code completion tools, and other AI-powered interfaces.
At the heart of this challenge lies a fundamental characteristic of auto-regressive models: their sequential nature of text generation. Unlike many computational processes that can benefit from parallel processing, these models face an architectural constraint that proves to be their primary performance bottleneck. To generate any given token K, the model must first process and consider all preceding tokens, from 1 to K-1, in sequential order. This dependency chain, which provides context for the text generation, creates a processing pipeline that cannot be easily parallelized.
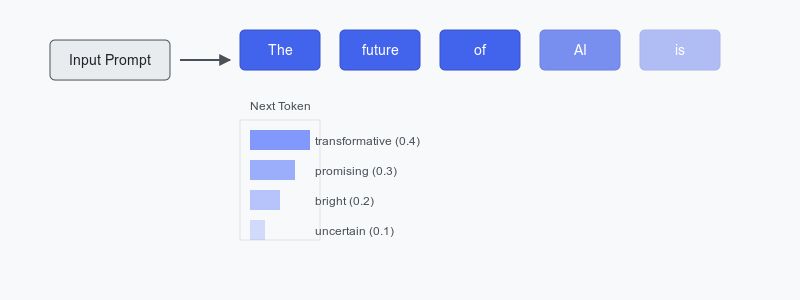
Consider the process illustrated in Figure 1, where each token's generation depends on the complete history of previous tokens. This sequential dependency isn't merely a technical limitation—it's a fundamental aspect of how these models understand and generate human-like text.
The situation becomes even more challenging when we scale up to larger models, particularly those exceeding 3+ billion parameters. These massive models, while offering superior capabilities in terms of reasoning, understanding, and generation, exact a significant performance penalty. Each token prediction requires more computational resources, as the model must process its vast parameter space for every single token generation step. The result is a compounding effect: not only must we handle the sequential nature of token generation, but each step in that sequence now takes longer due to the model's size.
Yet, despite these performance challenges, larger models remain indispensable for many applications. They excel at complex tasks that smaller models struggle with, such as multi-step reasoning, code generation, and nuanced understanding of context. They also produce higher-quality text with fewer artifacts and better coherence. This creates a tension between the need for sophisticated model capabilities and the practical requirements of production deployment.
In this solution, we will use speculative decoding to improve the performance of LLM deployments. It will allow us to improve the model latency without changing the model architecture, training data, or the trained model itself.
Solution
Speculative decoding is an optimization technique that leverages two distinct language models to improve generation speed while maintaining output quality. The approach uses a teacher-student architecture where two complementary models work together: a large, sophisticated language model (LLM) that produces highly accurate outputs but is computationally expensive and relatively slow, serving as the teacher model and ground truth for token generation; and a smaller, more efficient language model that operates faster but may be less accurate, acting as the student model. The student model is specifically trained to emulate the behavior of the teacher model – for example, a 3 billion parameter model might be trained to imitate a 405 billion parameter model.
The Inference Process
During text generation, the process follows a specific workflow. The student model begins by rapidly proposing a sequence of tokens based on its training to imitate the teacher model's behavior. Following this initial prediction, the teacher model evaluates the student's proposed tokens in parallel, verifying whether it would have generated the same sequence. The outcome of this validation determines the next steps: if the teacher model agrees with the student's predictions, the sequence is accepted and immediately output; however, if the teacher model disagrees, it falls back to its standard token-by-token generation process to ensure accuracy.
Key Insight
The fundamental principle behind speculative decoding is that not all tokens require the computational power of a large model for accurate generation. Token difficulty varies significantly – simple, predictable tokens like common words or obvious completions can be reliably generated by the smaller student model, while complex or context-dependent tokens benefit from the teacher model's advanced capabilities. This selective use of computational resources allows for significant speed improvements while maintaining the quality standards of the larger model. The approach is particularly effective because it balances the trade-off between speed and accuracy by dynamically choosing the appropriate model based on the complexity of the current generation task.
Here is an example of how speculative decoding would play out for a sequence of tokens:
Step 1:
Student: "The [talented] [chef]"
Teacher: ✓ Accepts (common phrase)
Step 2:
Student: "cooked [a] [delicious]"
Teacher: ✓ Accepts (common food context)
Step 3:
Student: "[soup]"
Teacher: ✗ Rejects
Teacher generates: "bouillabaisse" (rare, specific word)
Step 4:
Student: "[for] [dinner]"
Teacher: ✓ Accepts (common ending)
How does speculative decoding improve the inference speed?
We gain the inference speed increases by three aspects. First of all, we generate the proposal tokens through the smaller LLM. In addition, we can generate multiple tokens at once. We can request multiple tokens, since we have a second model to validate the predictions. We can afford it because the initial tokens predictions are fast and cheap. Secondly, the validation of the prediction is also fast, and we only need to correct the predictions for tokens where the smaller model made a mistake.
How can you use speculative decoding with your LLM? Most LLM deployment frameworks provide support of speculative decoding, in one form or another. For our core example, we are demonstrating speculative decoding with vLLM. vLLM is a frequently used framework for serving LLM models like Llama 3.2 3B. In our example, we use a smaller model to predict the next tokens and a larger model to validate the prediction and, if needed, correct the prediction. We use Meta's opt-125m model to predict the next tokens and the larger opt-2.7b model to validate the prediction and, if needed, correct the prediction. The sampling of the tokens, checking them with the larger model, and correcting them is done under the hood by the LLM serving framework, in our case vLLM.
from vllm import LLM, SamplingParams
prompts = [
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(
model="facebook/opt-2.7b",
tensor_parallel_size=1,
speculative_model="facebook/opt-125m",
num_speculative_tokens=5,
)
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
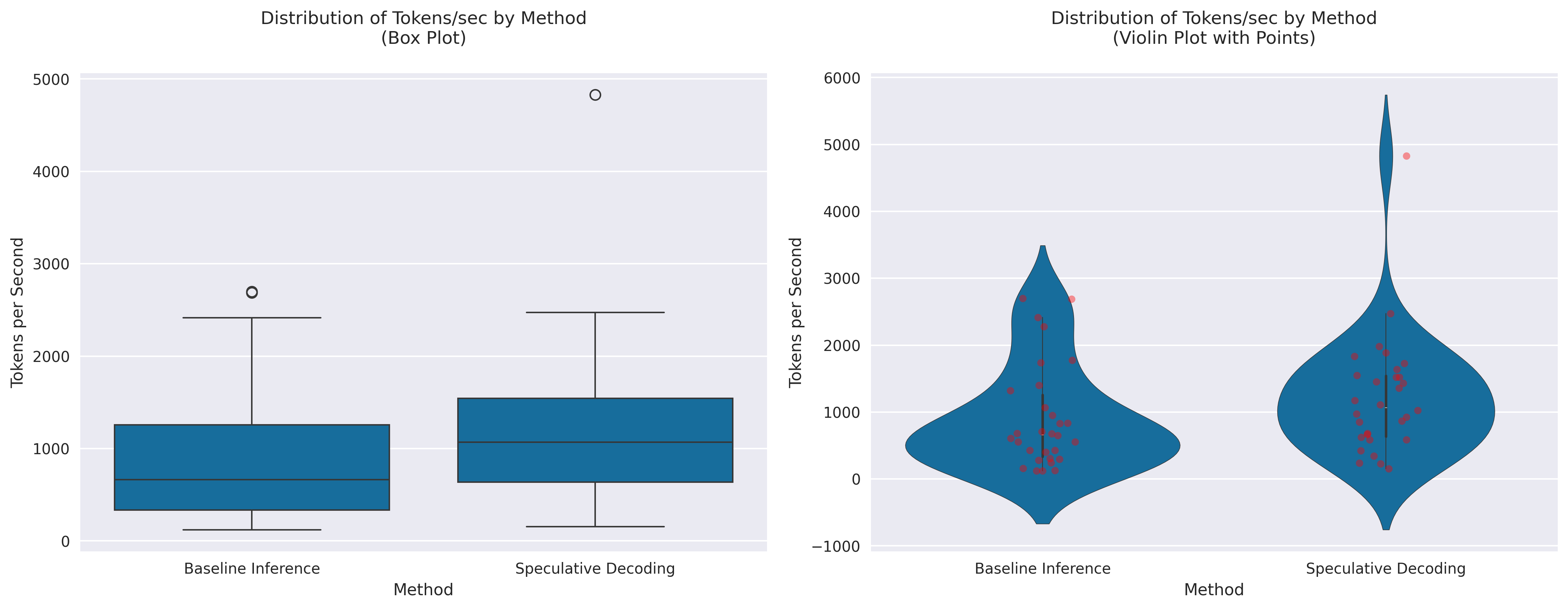
When we compare the latency of speculative decoding with the latency of the same model without speculative decoding, we can see that speculative decoding is faster by roughly 35% as we can see in Figure 2.
Trade-offs and Alternatives
There are significant trade-offs when using speculative decoding. The faster inferences don't come without downsides. In this section, we will discuss the trade-offs when using speculative decoding.
Sequence Length
The relationship between sequence length and performance gains in speculative decoding presents an interesting trade-off. Generally, longer sequences tend to yield higher speedups, as demonstrated in our example where we set num_speculative_tokens=5. This parameter allows the smaller model to predict multiple tokens ahead, potentially improving throughput. However, this advantage comes with diminishing returns: as sequence length increases, so does the likelihood of prediction errors. When these errors occur, the larger model steps in to correct the predictions, which can significantly slow down the overall inference process. Finding the optimal sequence length therefore requires careful balancing between maximizing the benefits of speculation while minimizing the computational overhead of error correction.
Larger Memory Footprint
The speculative decoding requires a larger memory footprint. The larger model needs to loaded into memory, together with the smaller model. This will require larger instances and GPUs, which translates to higher costs. Also, fine-tuning models is difficult for when you want to use speculative decoding with your models. The smaller model needs to be fine-tuned on the same dataset as the larger model. This is not always possible, since fine-tuning the larger model is more expensive than fine-tuning the smaller model (however, you might the performance boost from the smaller fine-tuned model already).
Model Pairing
A larger model needs to be paired with a smaller model using the same tokenization. This is no problem for larger models to be paired with smaller models. However, this is not the case for smaller models.
The following table shows the possible combinations of base models and smaller models for speculative decoding.
| Base Model | Smaller Model for suggesting tokens |
|---|---|
| Llama 3.1 405b | Llama 3.1 70B |
| Llama 3.1 405b | Llama 3.2 3B |
| Llama 3.1 405b | Llama 3.2 1B |
| Llama 3.3 70b | Llama 3.2 3B |
| Llama 3.3 70b | Llama 3.2 1B |
| Llama 3.2 3B | Llama 3.1 70B |
| Llama 3.2 1B | ? |
Problem specific Performance
The performance of speculative decoding also depends on the distribution of tokens. For example, if we want to generate English text for a chatbot, speculative decoding will be more effective than if we want to generate random hashes or bank transaction descriptions. in those cases, speculative decoding will actually be slower because the larger model needs to correct the predictions too often.
Alternatives
Several alternative approaches can help reduce LLM deployment latency, each with its own strengths and trade-offs.
Use a smaller model
The simplest approach is to use a smaller model altogether. This solution offers both reduced memory footprint and faster inference times compared to speculative decoding. The deployment becomes significantly simpler, requiring only one smaller model and less powerful GPUs. However, this approach comes with an obvious drawback: the quality of generated text suffers noticeably. While faster, smaller models often lack the sophisticated reasoning and nuanced understanding that larger models provide. You would typically only consider this option if your use case doesn't require the advanced capabilities of larger models.
Use a quantized model
Model quantization represents a sophisticated optimization technique that reduces numerical precision while preserving model functionality. By converting the model's parameters from their original 32-bit floating-point representation to 8-bit or even 4-bit precision post-training, quantization achieves significant improvements in both memory efficiency and computational performance. This reduction in numerical complexity translates directly into decreased memory footprint, lower computational overhead, and consequently, faster inference times.
While quantization does introduce a modest degradation in model quality compared to the original implementation, it offers compelling advantages as an alternative to speculative decoding. The deployment architecture remains streamlined with only a single model to maintain, and the reduced computational demands enable the use of more cost-effective GPU hardware. This balance of performance optimization and operational simplicity makes quantization an attractive option for many production environments.
Parallelization
Parallelization presents another powerful strategy for improving LLM performance of larger LLMs. Instead of processing multiple requests sequentially, you can process multiple requests simultaneously. This way, you can significantly decrease the effective latency across multiple requests. This approach particularly shines in high-traffic scenarios where individual requests use only a fraction of the model's context length. However, parallelization faces clear limitations: it remains constrained by both the model's maximum context length and the available GPU memory. Despite these constraints, parallelization often provides substantial performance benefits for many production deployments and it should be your first consideration when optimizing deployment latency.
Continuous batching
Continuous batching takes the parallelization concept even further. Instead of processing fixed batches, this technique dynamically pulls new requests from a queue whenever space becomes available in the current batch. This approach proves especially effective when handling a high volume of requests with varying context lengths. By maintaining consistent GPU utilization, continuous batching can achieve even lower latency than standard parallelization. However, it shares the same fundamental limitations regarding context length and GPU memory, and requires specialized deployment infrastructure to support the dynamic batching mechanism.
Caching
Caching offers a different approach to latency optimization, particularly valuable for applications with repetitive requests. By storing and reusing previous inference results for identical prompts, caching can deliver nearly instantaneous responses for repeated queries. While novel requests still face slow inference time of a large model, frequently accessed responses become lightning-fast. This makes caching particularly effective for applications like customer service chatbots or code completion tools, where certain queries appear frequently. The effectiveness of caching directly correlates with the repetitiveness of your workload – the more repeated queries you handle, the greater the performance benefit.
Demo
We have created a demo of speculative decoding with vLLM. You can find the code in Colab.
Conclusion
Speculative decoding is a promising technique to improve the performance of LLM deployments. in our demo example, we were able to improve the latency by 35%. However, it comes with a larger memory footprint and more deployment complexity.