Vibe coding is killing open source, but not how you think
Why we need a renaissance of open source
A few years ago, I was a contributor to TensorFlow Extended, and once a week, the contributors got on a call. We'd argue about API design, complain about whatever was broken that week, and talk about where the industry was heading. Some of us worked at Google. Some of us worked at companies that competed with Google. None of that mattered for the forty-five minutes we were on the call. Over time, we built something that's harder to describe than it is to feel: a network of people across companies who actually trusted each other. We met up at conferences. We shared what we were learning. We pushed each other to be better.
That kind of weekly call still happens in some projects. But the world that produced it is quietly changing, and I don't think most engineers have noticed yet.
Today's internet runs on open source. Linux on the servers, nginx and Apache in front of them, Postgres underneath. Apache Kafka, originally built at LinkedIn, moves data around for basically every SaaS company you've used. A long list of open source projects became the foundation for huge commercial ones: Apache Beam shaped Google Cloud Dataflow, Apache Flink powers parts of AWS, and the entire AI stack — PyTorch, TensorFlow, Keras, vLLM — is open source. So the stakes here are not abstract.
With the rise of vibe coding, it is now faster to spin up a project from scratch for your own use case than to submit a patch to an existing one and let everyone benefit. You can see this in GitHub activity [1] [2]: where contributions used to be dominated by changes to existing code, the ratio has flipped toward greenfield projects, which is exactly the kind of work where Claude and Codex shine [3].
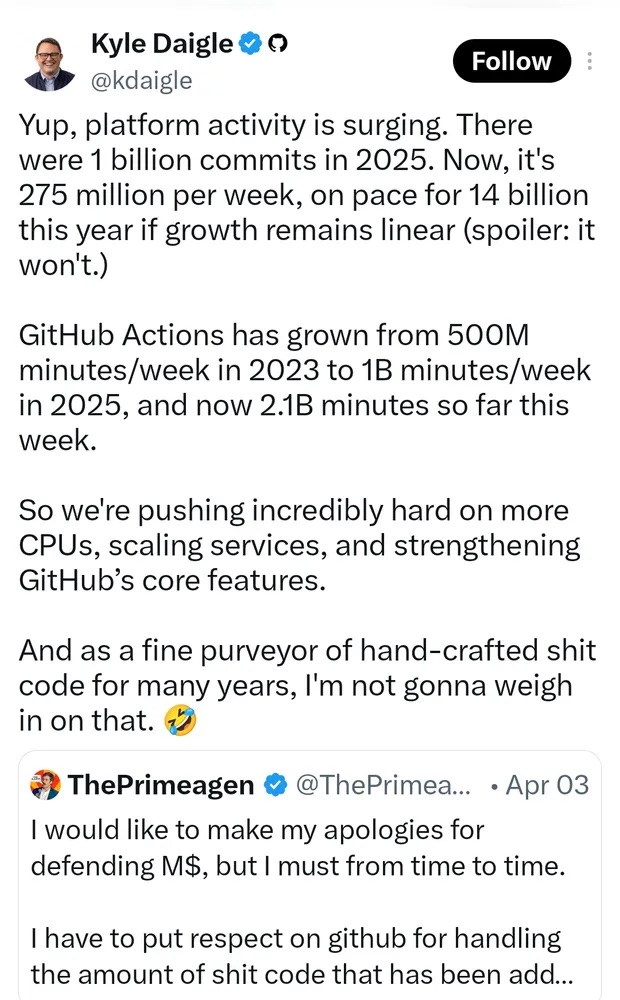
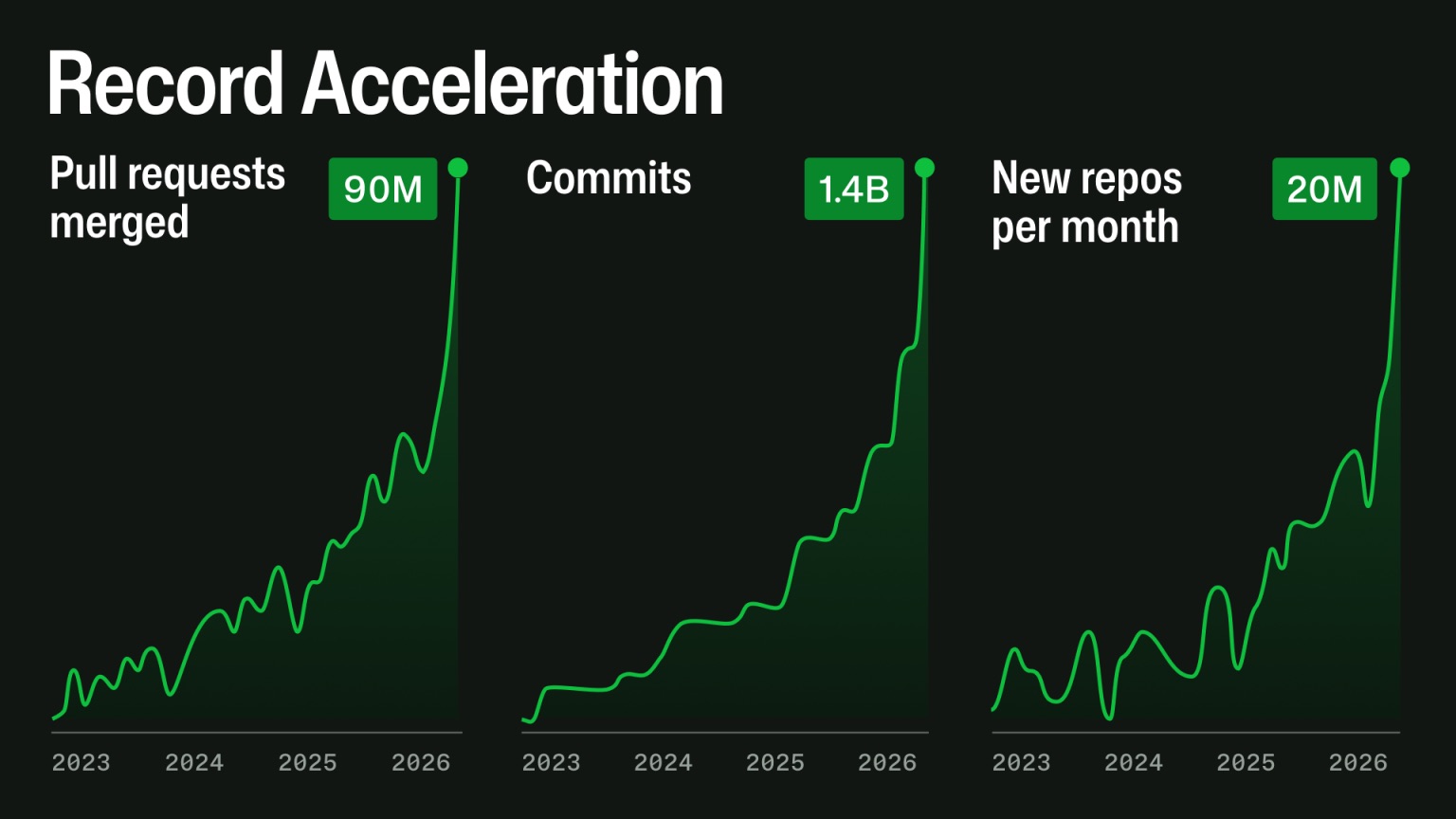
At the same time, the projects that do still get patches are flooded with PRs from coding agents. Before vibe coding, over 80% of contributions came from one-time committers [4]. Someone hit a bug in their favorite library, fixed it, watched the merge, and moved on. That was fine, because the remaining 20% had a long-term interest in the project, and that was usually enough to keep things going (though it still left a heavy load on core maintainers).
Now the ratio is worse. A small fraction of contributions come from people with any long-term interest in the project. Some maintainers have responded by banning agent contributions outright — the Zig project, for example [5]. The reason isn't that the code is always bad. In some cases it's actually well structured and even improves the docs. The reason is that something quieter goes missing: mentorship. Junior developers learned the craft by contributing to established projects. Maintainers, often without realizing it, were training their own successors. It was a slow, durable win-win, and it's the part that doesn't show up in a commit graph.
So here's where we are: quick vibe coding is replacing long-term contribution, and a whole community (a whole mindset, really) is fading with it.
It isn't too late to fix this. But to see why it's worth fixing, it helps to remember what open source actually gives us.
The web and the AI stack both benefited from open source in ways that are easy to take for granted. When a new attention mechanism drops, patches land in PyTorch and vLLM within hours. That isn't just technical excellence. It's trust. A broad community of people, none of whom answer to the same boss, decided the change was worth shipping.
And it isn't only the trust that updates will arrive quickly. It's the trust that you can read every line if you need to. (Less true for open-weight models, but the principle still holds for the surrounding infrastructure.) That trust is quietly carrying a lot of the economy. It's why you can hand your credit card to a checkout page and assume the nginx config in front of it isn't doing something hostile. It's why you can run an ML evaluation and assume the framework isn't quietly cooking the numbers. Imagine a Volkswagen-style emissions scandal, but for model benchmarks. The reason that hasn't happened isn't a clever piece of regulation. It's that thousands of people have read the code.
Open source is trust.
And trust matters more, not less, in a world where tech is increasingly controlled by a handful of companies.
None of this is anti-AI. I use Claude every day, including for my open source work. It's great for the boring parts. The problem isn't agents writing code. The problem is what happens when only agents write code for the projects we all depend on, and the humans who used to mentor each other through those codebases drift away.
Open source has always been carried by a small core of maintainers and a long tail of people who showed up, learned something, and stuck around. Vibe coding is great at producing the first commit. It's pretty bad at producing the fifth-year contributor who eventually takes over the project.
So: fund this work. With headcount. With paid time for your engineers to maintain the libraries your company runs on. A few companies are starting to do this seriously. (Disclosure: I work at one of them, Dataiku, which set up an open source lab last year. I'd rather see ten more.) The specific projects matter less than the pattern: treat the commons like infrastructure, because that's what it is. For a more in-depth economic argument, this paper [6] is worth your time.
Open source is trust. Trust gets built by humans showing up for each other over years. That's the part no agent can vibe-code for us.
References
- GitHub Blog. An Update on GitHub Availability. github.blog
- cameron.stream. Post on Bluesky. bsky.app
- Hacker News. Discussion thread 46142841. news.ycombinator.com
- Eghbal, Nadia. Working in Public. Stripe Press, 2020.
- Zig Project. Code of Conduct. ziglang.org
- Paper on arXiv. ID 2601.15494. arxiv.org